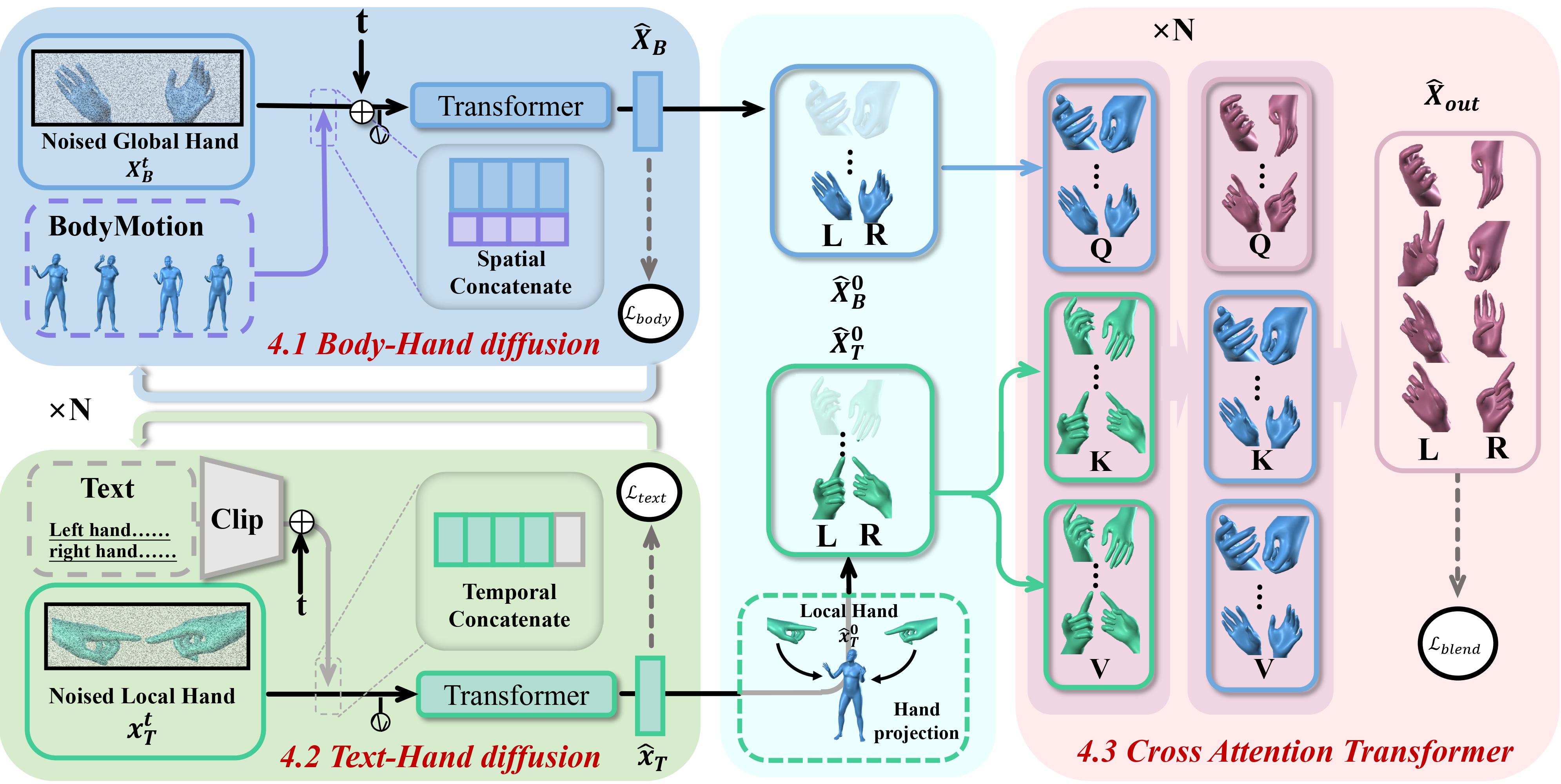
BOTH57M, a unique body-hand motion dataset comprising 1,384 motion clips and 57.4M frames, with 23,477 manually annotated motions and a rich vocabulary of 4,140 words, focusing on hands and body motion in daily various activities, referencing the book "Dictionary of Gestures" and supplementing with custom-designed movements. To the best of our knowledge, this is the only dataset that provides hybrid and detailed annotations of both body and hands at present, providing infinite possibilities for future tasks. The rich vocabulary and hand diversity underscores our advantage in tackling the text-body to hand task.
@inproceedings{zhang24both,
title = {BOTH2Hands: Inferring 3D Hands from Both Text Prompts and Body Dynamics},
author = {Zhang, Wenqian and Huang, Molin and Zhou, Yuxuan and Zhang, Juze and Yu, Jingyi and Wang, Jingya and Xu, Lan},
booktitle = {Conference on Computer Vision and Pattern Recognition ({CVPR})},
year = {2024},
}